
The Missing Piece In Vulnerability Management
I would like to share my views on one of the biggest challenges I see in the vulnerability management (VM) space; and how MITRE CAPEC is part of the solution to that problem.
I've been in pen testing for the last decade, helping companies establish and improve their pen testing programs. I've worked for a large consultancy; run my own consultancy; and more recently as one of the co-founders at AttackForge, focusing on process improvement for pentesting.
Firstly, let's start with: what is vulnerability management?
Vulnerability management is the process of identifying, normalizing, evaluating, treating, and then reporting on security vulnerabilities in systems.
Organizations have large teams dedicated to just this. They collect data and report back to executives to inform if the company is getting better or worse at closing security gaps.
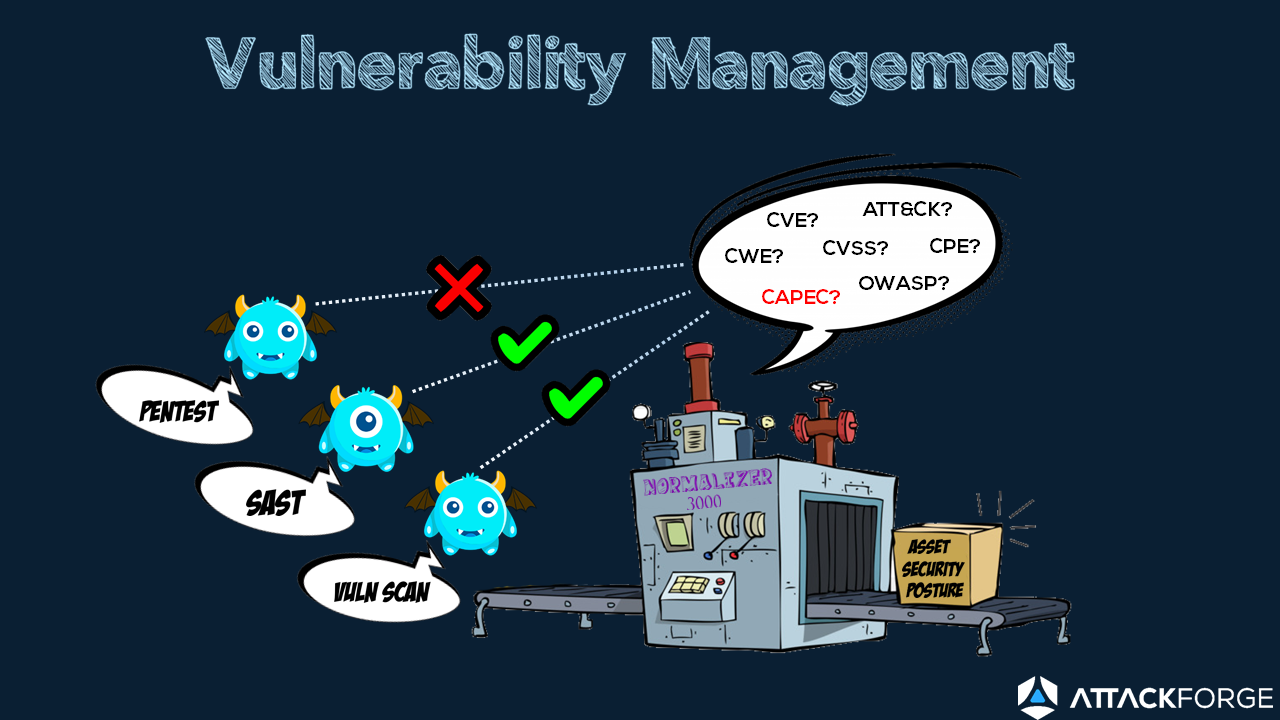
When we consider what data goes into vulnerability management, we should consider data from vulnerability scanners; static analysis tools; as well as pen test findings.
However, most organizations fail to incorporate pen test data into vulnerability management. There's good reason for it, but first: why is it a problem?
Pen testing data usually results in complex and arbitrary vulnerabilities. For example, zero-day vulnerabilities or vulnerabilities in business logic. If vulnerability management can't see these often-critical vulnerabilities, they likely never get fixed.
In vulnerability management - vulnerabilities are the input. Tools do all the crunching and normalization. The output is known security posture for an asset. Risk teams use this when deciding what to fix and when.
Vulnerability scanners and SAST tools usually include industry references and tags when registering vulnerabilities in VM tools, such as CAPEC, CWE, and CVE. This allows for efficient and effective normalization.
When it comes to pen test findings, at most you might get a CVSS, and that alone is not enough to normalize the data.
Pen test findings mostly will not have a CVE, and may have a CAPEC or CWE, if your pen testers like you. And to make matters worse - pen test data is arbitrarily defined based on how the pen tester feels at the time.
This makes normalization impossible.
Most VM tools struggle to bring pen test data into vulnerability management.
The deliverable from a pen test is usually a static PDF or Doc report. Pentesters spend days and weeks creating the perfect report, to avoid making the report feel pre canned. You’re not going to get the same report from two different vendors, or even two different pen testers.
You can see for yourself if you search in Google for “GitHub Pen Test reports”. The first link you'll find is to GitHub Julio Cesar Fort public repository, which is quite popular. It has samples from companies all over the world. You can browse through each one and you'll start to see the problem - inconsistency in pen test data, causing a major bottleneck for vulnerability management.
How do we turn those static reports into normalized findings?
The definitions and recommendations for vulnerabilities change between each pentester or QA. There's no easy way to determine if they are the same ones you are tracking in VM.
Even if you receive the data in a consistent format with CVSS, CWE and CAPEC references, how do you get that into your VM tools to process it? They were never designed to deal with arbitrary data or multiple tagging.
This combination of problems, starting with how pen testing is done, the deliverables and the output, to the current state of VM tools, implies that pen test data is unlikely to be included in your VM.
So how do we actually fix it?
Firstly, we need an industry standard for tagging pen test findings. Something easy to understand and use, which VM tools can incorporate – similar to CVE and CVSS.
This standard would need to handle different types of vulnerabilities – application, API, infrastructure, mobile, thick clients, IoT, etc. I see CAPEC as a natural fit to solving this.
We need to train people to use this standard. This would finally allow to compare apples with apples.
Once we have standardized tagging and structured vulnerability fields, we need to get this to security teams in machine readable formats.
Finally, VM tools can incorporate this into their processes, and normalize pentest findings. Humans will be able to see pen test vulnerabilities inside VM, action and report on them. Ultimately more things will get fixed.
In summary – I consider the solution to this problem is standardization and collaboration. We need to work together and not against each other to stay one step ahead of the bad folks.